大数据
1、 NAMENODE职责
(1)负责客户端请求的响应
(2)元数据的管理(查询,修改)
2、元数据的存储机制
A、内存中有一份完整的元数据(内存metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
3.Hadoop分布式集群,默认备份数为多少,每个数据块大小是多少?在哪个配置文件中可以修改备份数与每个数据块大小?
默认备份为3份,每块数据大小128M, 在hdfs-site.xml配置文件中可以修改备份数和数据块大小。
<property> <name>dfs.block.size</name> <value>128</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property>
4、MapReduce的原理和执行过程
(1)Mapper任务的运行过程分为六个阶段。
第一阶段是把输入文件按照一定的标准分片 (InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片,一共产生三个输入片。每一个输入片由一个Mapper进程处理,这里的三个输入片,会有三个Mapper进程处理。
第二阶段是对输入片中的记录按照一定的规则解析成键值对,有个默认规则是把每一行文本内容解析成键值对,这里的“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
第三阶段是调用Mapper类中的map方法,在第二阶段中解析出来的每一个键值对,调用一次map方法,如果有1000个键值对,就会调用1000次map方法,每一次调用map方法会输出零个或者多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区,分区是基于键进行的,比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认情况下只有一个区,分区的数量就是Reducer任务运行的数量,因此默认只有一个Reducer任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值 对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果 是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux 文件中。
第六阶段是对数据进行归约处理,也就是reduce处理,通常情况下的Comber过程,键相等的键值对会调用一次reduce方法,经过这一阶段,数据量会减少,归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
(2)Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。
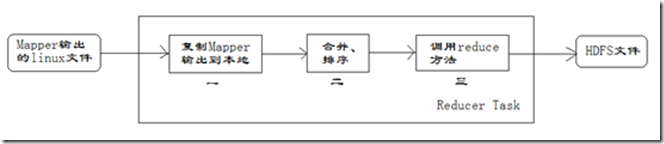
1、第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对,Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
2、第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据,再对合并后的数据排序。
3、第三阶段是对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
5、Spark RDD是如何容错的,原理是什么?
Spark框架层面的容错机制,主要分为三大层面(调度层、RDD血统层、Checkpoint层),在这三大层面中包括Spark RDD容错四大核心要点。
(1)Stage输出失败,上层调度器DAGScheduler重试。
(2)Spark计算中,Task内部任务失败,底层调度器重试。
(3)RDD Lineage血统中窄依赖、宽依赖计算。
(4)Checkpoint缓存。
6、spark的三种模式的详细运行过程
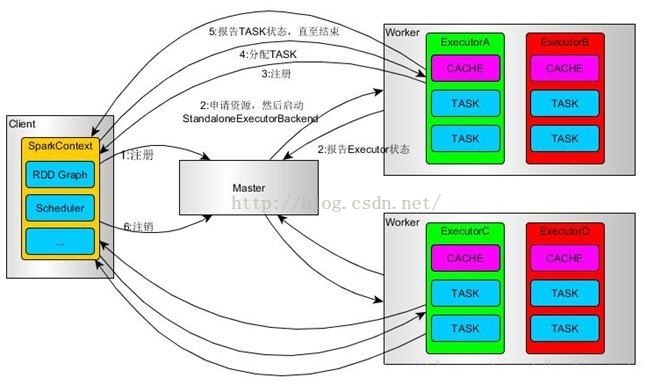
(一)Standalone模式
(1)使用SparkSubmit提交任务的时候(包括Eclipse或者其它开发工具使用new SparkConf()来运行任务的时候),Driver运行在Client;使用SparkShell提交的任务的时候,Driver是运行在Master上
(2)使用SparkSubmit提交任务的时候,使用本地的Client类的main函数来创建sparkcontext并初始化它;
(3)SparkContext连接到Master,注册并申请资源(内核和内存)。
(4)Master根据SC提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动StandaloneExecutorBackend(executor)
(5)executor向SC注册
(6)SC将应用分配给executor,
(7)SC解析应用,创建DAG图,提交给DAGScheduler进行分解成stage(当出发action操作的时候,就会产生job,每个job中包含一个或者多个stage,stage一般在获取外部数据或者shuffle之前产生)。然后stage(又称为Task Set)被发送到TaskScheduler。TaskScheduler负责将stage中的task分配到相应的worker上,并由executor来执行
(8)executor创建Executor线程池,开始执行task,并向SC汇报
(9)所有的task执行完成之后,SC向Master注销
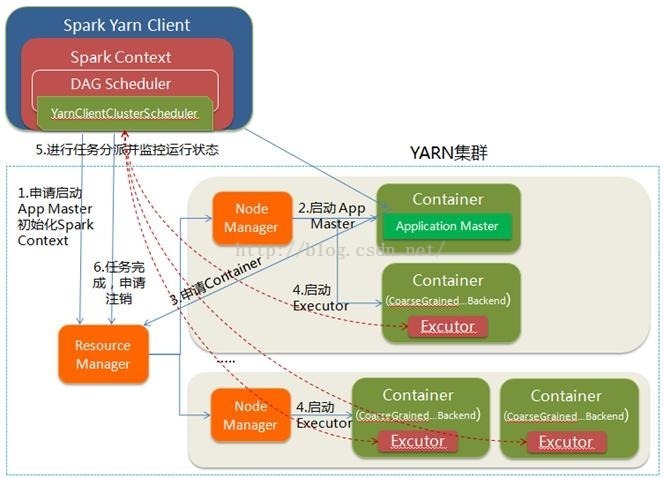
(二)yarn client模式
(1)spark-submit脚本提交,Driver在客户端本地运行;
(2)Client向RM申请启动AM,同时在SC(client上)中创建DAGScheduler和TaskScheduler。
(3)RM收到请求之后,查询NM并选择其中一个,分配container,并在container中开启AM
(4)client中的SC初始化完成之后,与AM进行通信,向RM注册,根据任务信息向RM申请资源
(5)AM申请到资源之后,与AM进行通信,要求在它申请的container中开启CoarseGrainedExecutorBackend(executor)。Executor在启动之后会向SC注册并申请task
(6)SC分配task给executor,executor执行任务并向Driver(运行在client之上的)汇报,以便客户端可以随时监控任务的运行状态
(7)任务运行完成之后,client的SC向RM注销自己并关闭自己
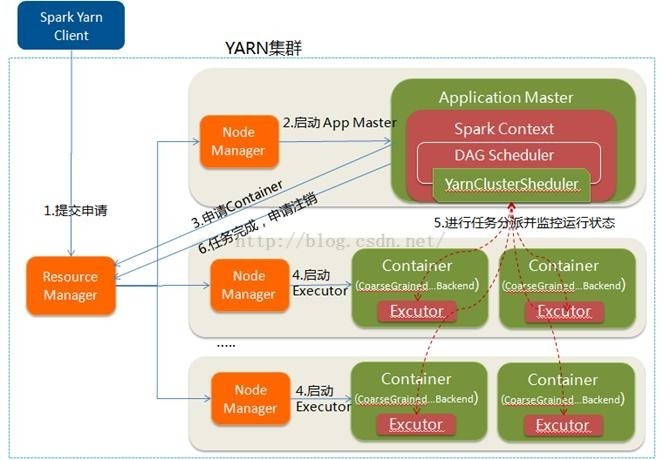
(三)yarn cluster模式
(1)spark-submit脚本提交,向yarn(RM)中提交ApplicationMaster程序、AM启动的命令和需要在Executor中运行的程序等
(2)RM收到请求之后,选择一个NM,在其上开启一个container,在container中开启AM,并在AM中完成SC的初始化
(3)SC向RM注册并请求资源,这样用户可以在RM中查看任务的运行情况。RM根据请求采用轮询的方式和RPC协议向各个NM申请资源并监控任务的运行状况直到结束
(4)AM申请到资源之后,与对应的NM进行通信,要求在其上获取到的Container中开启CoarseGrainedExecutorBackend(executor), executor 开启之后,向AM中的SC注册并申请task
(5)AM中的SC分配task给executor,executor运行task并向AM中的SC汇报自己的状态和进度
(6)应用程序完成之后(各个task都完成之后),AM向RM申请注销自己并关闭自己
7、Kafka的ACK
(1)如何保证宕机的时候数据不丢失?
如果要想理解这个acks参数的含义,首先就得搞明白kafka的高可用架构原理。
比如下面的图里就是表明了对于每一个Topic,我们都可以设置他包含几个Partition,每个Partition负责存储这个Topic一部分的数据。
然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。

但是有一个问题,万一 一个Kafka Broker宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是他首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
(2)多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说zookeeper、kafka、redis cluster、elasticsearch、hdfs,等等,其实他都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在kafka集群中,每个Partition都有多个副本,其中一个副本叫做leader,其他的副本叫做follower,如下图。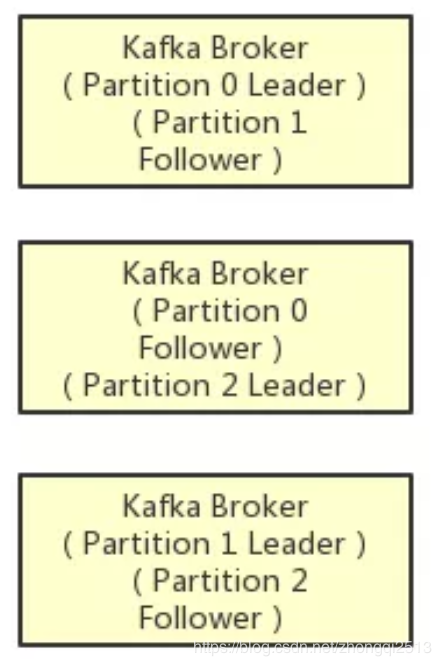
如上图所示,假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本。
比如Partition0有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
(3)多副本之间数据如何同步?
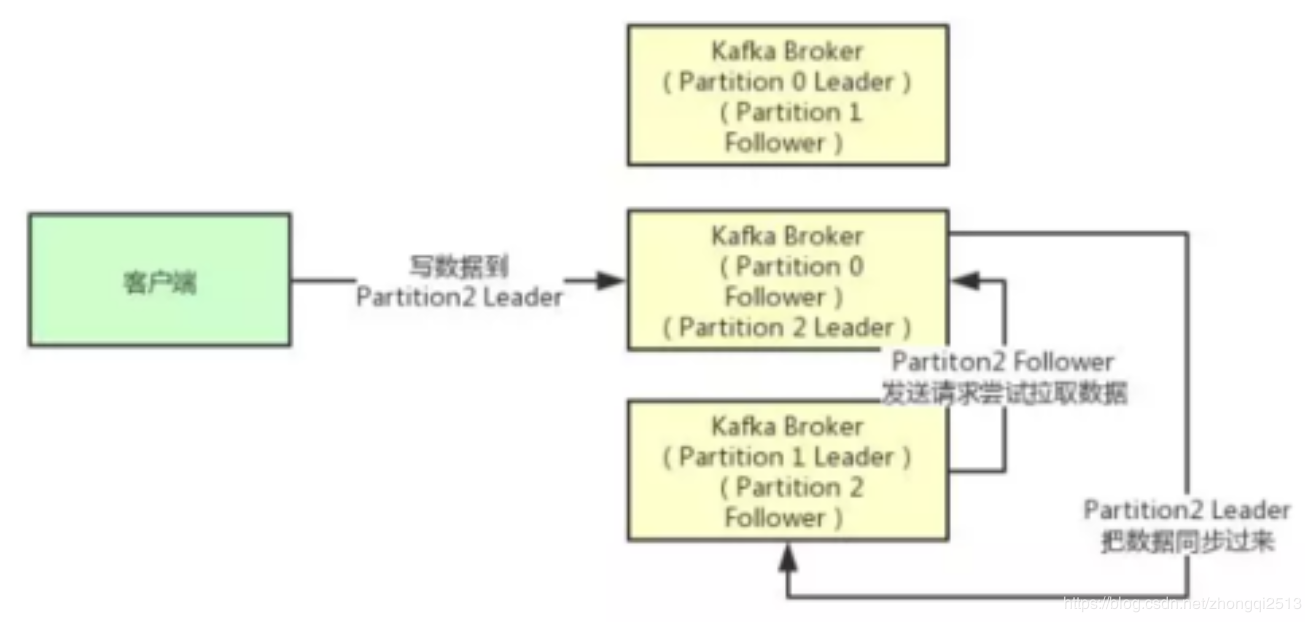
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个Partition,只有Leader是对外提供读写服务的
也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。如下图所示:
(4)ISR到底指的是什么东西?
既然大家已经知道了Partiton的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
大家可以想一下 ,如果说某个Follower所在的Broker因为JVM FullGC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower的数据比Leader要落后很多?
所以这个时候,就意味着Follower已经跟Leader不再处于同步的关系了。但是只要Follower一直及时从Leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。
(5)acks参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下acks参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR机制,那么就无法充分的理解acks参数的含义,这个参数实际上决定了很多重要的东西。
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的
也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
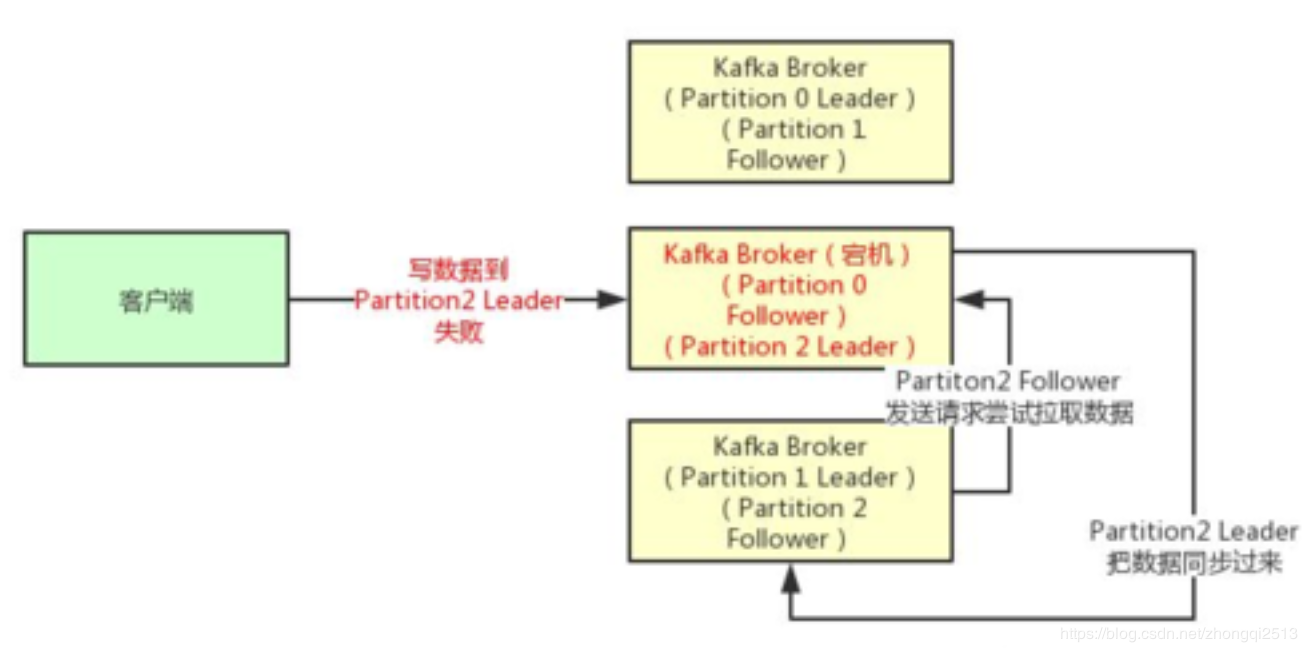
第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
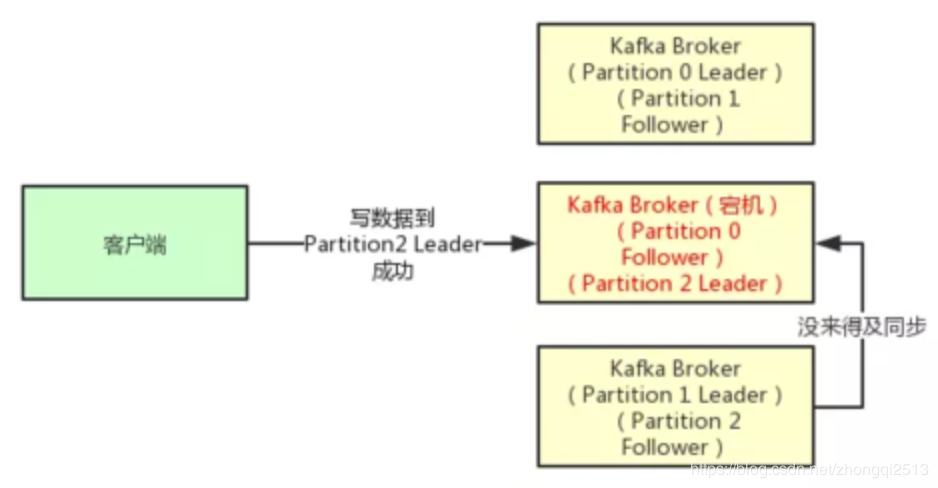
第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
 最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。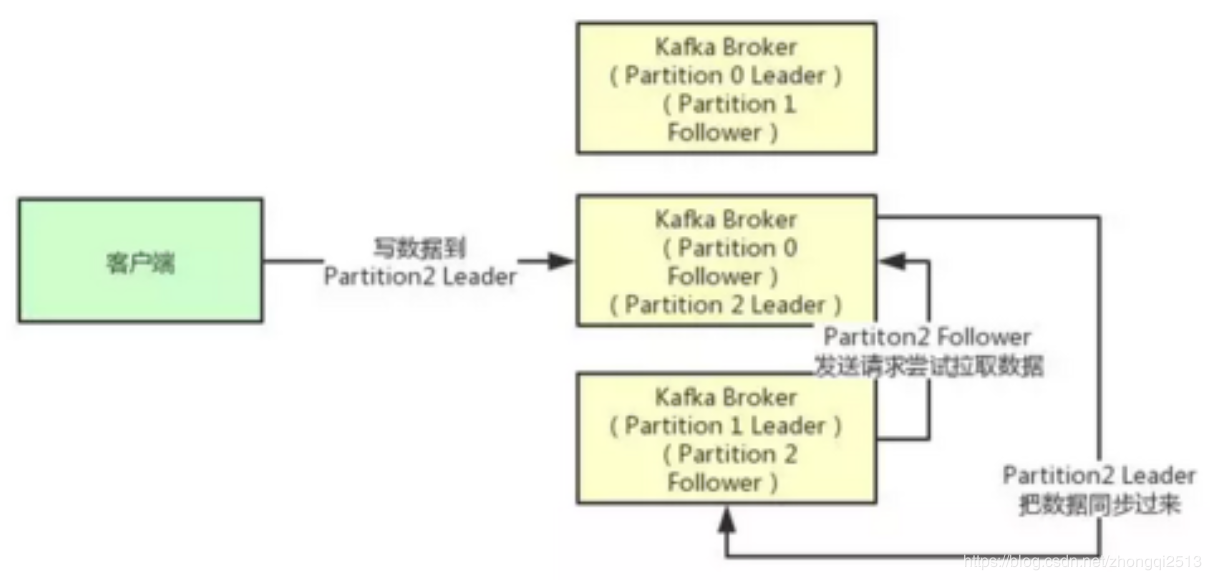
(6)最后的思考
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
8、Hive如何实现组内排序
使用row_number() over (partition by field1 order by field2 desc)进行组内排序,field1作为分组字段,field2作为排序字段。整个值作为排序后的序号
9、spark reduceByKey和groupByKey区别,用法以及性能对比
(1)reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
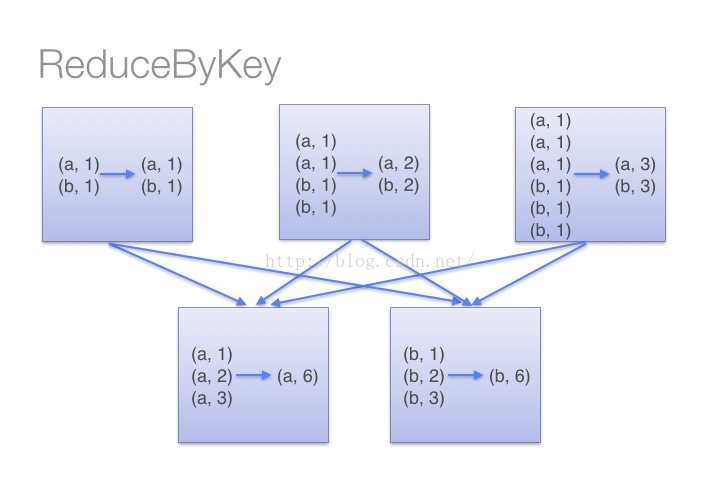
(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
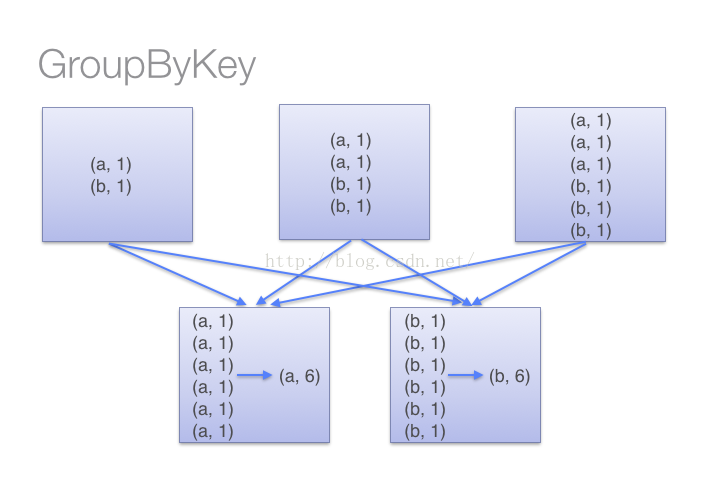
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
10、kafka如何保证数据不丢失
Kafka的ack机制,指的是producer的消息发送确认机制,这直接影响到Kafka集群的吞吐量和消息可靠性。而吞吐量和可靠性就像硬币的两面,两者不可兼得,只能平衡。
ack有3个可选值,分别是1,0,-1。
ack=1,简单来说就是,producer只要收到一个分区副本成功写入的通知就认为推送消息成功了。这里有一个地方需要注意,这个副本必须是leader副本。只有leader副本成功写入了,producer才会认为消息发送成功。
注意,ack的默认值就是1。这个默认值其实就是吞吐量与可靠性的一个折中方案。生产上我们可以根据实际情况进行调整,比如如果你要追求高吞吐量,那么就要放弃可靠性。
ack=0,简单来说就是,producer发送一次就不再发送了,不管是否发送成功。
ack=-1,简单来说就是,producer只有收到分区内所有副本的成功写入的通知才认为推送消息成功了。
11、hadoop的shuffle过程
(1)Map端的shuffle
Map端会处理输入数据并产生中间结果,这个中间结果会写到本地磁盘,而不是HDFS。每个Map的输出会先写到内存缓冲区中,当写入的数据达到设定的阈值时,系统将会启动一个线程将缓冲区的数据写到磁盘,这个过程叫做spill。
在spill写入之前,会先进行二次排序,首先根据数据所属的partition进行排序,然后每个partition中的数据再按key来排序。partition的目是将记录划分到不同的Reducer上去,以期望能够达到负载均衡,以后的Reducer就会根据partition来读取自己对应的数据。接着运行combiner(如果设置了的话),combiner的本质也是一个Reducer,其目的是对将要写入到磁盘上的文件先进行一次处理,这样,写入到磁盘的数据量就会减少。最后将数据写到本地磁盘产生spill文件(spill文件保存在{mapred.local.dir}指定的目录中,Map任务结束后就会被删除)。
最后,每个Map任务可能产生多个spill文件,在每个Map任务完成前,会通过多路归并算法将这些spill文件归并成一个文件。至此,Map的shuffle过程就结束了。
(2)Reduce端的shuffle
Reduce端的shuffle主要包括三个阶段,copy、sort(merge)和reduce。
首先要将Map端产生的输出文件拷贝到Reduce端,但每个Reducer如何知道自己应该处理哪些数据呢?因为Map端进行partition的时候,实际上就相当于指定了每个Reducer要处理的数据(partition就对应了Reducer),所以Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据即可。每个Reducer会处理一个或者多个partition,但需要先将自己对应的partition中的数据从每个Map的输出结果中拷贝过来。
接下来就是sort阶段,也成为merge阶段,因为这个阶段的主要工作是执行了归并排序。从Map端拷贝到Reduce端的数据都是有序的,所以很适合归并排序。最终在Reduce端生成一个较大的文件作为Reduce的输入。
最后就是Reduce过程了,在这个过程中产生了最终的输出结果,并将其写到HDFS上。
12、HDFS读写数据的过程
读:
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
写:
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
13、rdd 怎么分区宽依赖和窄依赖
宽依赖:父RDD的分区被子RDD的多个分区使用 例如 groupByKey、reduceByKey、sortByKey等操作会产生宽依赖,会产生shuffle
窄依赖:父RDD的每个分区都只被子RDD的一个分区使用 例如map、filter、union等操作会产生窄依赖
14、spark streaming 读取kafka数据的两种方式
这两种方式分别是:
Receiver-base
使用Kafka的高层次Consumer API来实现。receiver从Kafka中获取的数据都存储在Spark Executor的内存中,然后Spark Streaming启动的job会去处理那些数据。然而,在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以使用预写日志中的数据进行恢复。
Direct
Spark1.3中引入Direct方式,用来替代掉使用Receiver接收数据,这种方式会周期性地查询Kafka,获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumerapi来获取Kafka指定offset范围的数据。
15、kafka的数据存在内存还是磁盘
Kafka最核心的思想是使用磁盘,而不是使用内存,可能所有人都会认为,内存的速度一定比磁盘快,我也不例外。在看了Kafka的设计思想,查阅了相应资料再加上自己的测试后,发现磁盘的顺序读写速度和内存持平。
16、Kafka 数据丢失和数据重复的原因和解决办法
数据丢失的原因
Kafka 消息发送分同步 (sync)、异步 (async) 两种方式,默认使用同步方式,可通过 producer.type 属性进行配置;
通过 request.required.acks 属性进行配置:值可设为 0, 1, -1(all) -1 和 all 等同
0 代表:不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
1 代表:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据;
-1 代表:producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才返回 ack,数据一般不会丢失,延迟时间长但是可靠性高;但是这样也不能保证数据不丢失,比如当 ISR 中只有 leader 时( ISR 中的成员由于某些情况会增加也会减少,最少就只剩一个 leader),这样就变成了 acks = 1 的情况;
另外一个就是使用高级消费者存在数据丢失的隐患: 消费者读取完成,高级消费者 API 的 offset 已经提交,但是还没有处理完成Spark Streaming 挂掉,此时 offset 已经更新,无法再消费之前丢失的数据. 解决办法使用低级消费者
数据重复的原因
acks = -1 的情况下,数据发送到 leader 后 ,部分 ISR 的副本同步,leader 此时挂掉。比如 follower1 和 follower2 都有可能变成新的 leader, producer 端会得到返回异常,producer 端会重新发送数据,数据可能会重复
另外, 在高阶消费者中,offset 采用自动提交的方式, 自动提交时,假设 1s 提交一次 offset 的更新,设当前 offset = 10,当消费者消费了 0.5s 的数据,offset 移动了 15,由于提交间隔为 1s,因此这一 offset 的更新并不会被提交,这时候我们写的消费者挂掉,重启后,消费者会去 ZooKeeper 上获取读取位置,获取到的 offset 仍为10,它就会重复消费. 解决办法使用低级消费者
数据丢失的解决办法
设置同步模式, producer.type = sync, Request.required.acks = -1, replication.factor >= 2 且 min.insync.replicas >= 2
17、datanode首次加入 cluster 的时候,如果 log 报告不兼容文件版本,那需要namenode 执行格式化操作,这样处理的原因是?
1)这样处理是不合理的,因为那么 namenode格式化操作,是对文件系统进行格式化,namenode 格式化时清空 dfs/name 下空两个目录下的所有文件,之后,会在目录 dfs.name.dir 下创建文件。
2)文本不兼容,有可能时 namenode 与 datanode 的 数据里的 namespaceID、clusterID 不一致,找到两个 ID 位置,修改为一样即可解决。
18、MapReduce中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
1)一个 MapReduce 作业由 Map 阶段和 Reduce 阶段两部分组成,这两阶段会对数据排序,从这个意义上说,MapReduce 框架本质就是一个 Distributed Sort。
2)在 Map 阶段,Map Task 会在本地磁盘输出一个按照 key 排序(采用的是快速排序)的文件(中间可能产生多个文件,但最终会合并成一个),在Reduce 阶段,每个 Reduce Task 会对收到的数据排序,这样,数据便按照 Key 分成了若干组,之后以组为单位交给 reduce()处理。
3)很多人的误解在 Map 阶段,如果不使用 Combiner便不会排序,这是错误的,不管你用不用 Combiner,Map Task 均会对产生的数据排序(如果没有 Reduce Task,则不会排序,实际上 Map 阶段的排序就是为了减轻 Reduce端排序负载)。
4)由于这些排序是 MapReduce 自动完成的,用户无法控制,因此,在hadoop 1.x 中无法避免,也不可以关闭,但 hadoop2.x 是可以关闭的。
19、Hbase的读写流程是怎么样的?
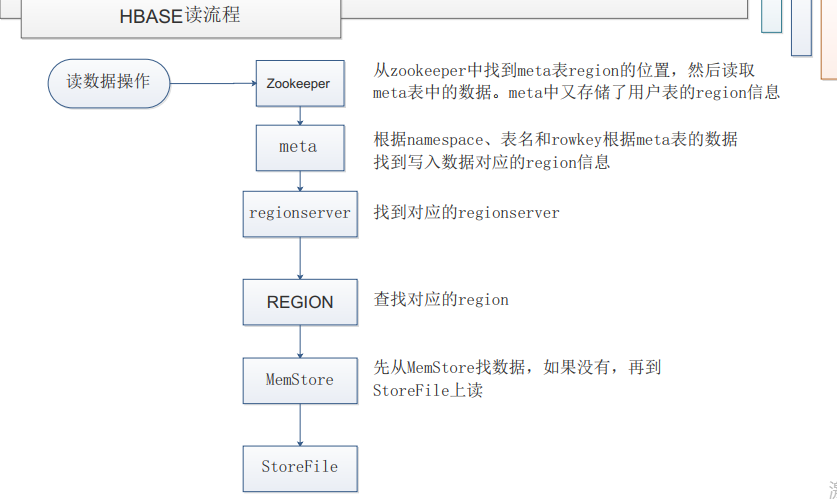
(一)hbase的读操作:
ZooKeeper---meta--regionserver--region--memstore--storefile
1、首先从zookerper找到meta表的region的位置,然后读取meta表中的数据。而meta中又存储了用户表的region信息
2、根据namespace、表名和rowkey根据meta表中的数据找到写入数据对于的region信息
3、然后找到对于的regionserver
4、查找对应的region
5、先从Memstore找数据,如果没有,再到StoreFile上读
(二)hbase的写操作:
ZooKeeper---meta--regionserver--1、Hlog 1、MemStore--storefile
1、首先从zookerper找到meta表的region的位置,然后读取meta表中的数据。而meta中又存储了用户表的region信息
2、根据namespace、表名和rowkey根据meta表中的数据找到写入数据对于的region信息
3、然后找到对于的regionserver
4、把数据分别写到Hlog和memstore各一份
4、1当memstore达到阈值后把数据刷成一个storefile文件,当compact后,逐渐形成越来越大的storefile后触发spilt,
把当前的StoreFile分成两个,这里相当于把一个大的region分割成两个region
4、1若MemStore中的数据有丢失,则可以从HLog上恢复,当多个StoreFile文件达到一定的大小后,会触发Compact合并操作,
合并为一个StoreFile,这里同时进行版本的合并和数据删除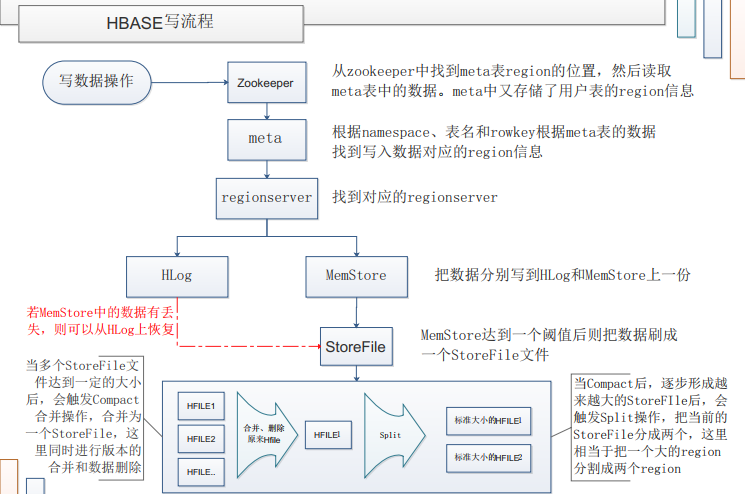
20、Hive分区过多有何坏处以及分区时的注意事项?
1.当分区过多且数据很大时,可以使用严格模式,避免出发一个大的mapreduce任务。当分区数量过多且数据量较大时,执行宽范围的数据扫描会触发一个很大的mapreduce任务。在严格模式下,当where中没有分区过滤条件时会禁止执行。
2.hive如果有过多的分区,由于底层是存储在HDFS上,HDFS上只用于存储大文件 而非小文件,因为过多的分区会增加namenode的负担。
3.hive会转化为mapreduce,mapreduce会转化为多个task。过多小文件的话,每个文件一个task,每个task一个JVM实例,JVM的开启与销毁会降低系统效率。
21、Hive中复杂数据类型的使用好处与坏处?
好处:由于复杂数据类型的存储数据比基本数据类型要多,在存盘上存储可以连续存储,在查询等操作时可以减少磁盘IO。
坏处:复杂数据类型可能会存在着数据的重复,而且有更大的导致数据不一致的风险。
22、Hive什么情况下可以避免进行MapReduce?
1、本地模式下,hive可以简单的读取目录路径下的数据,然后输出格式化后的数据到控制台,比如有本地员工employee,当执行 select * from employee 时,直接将文件中数据格式化输出。
2、查询语句中的过滤条件只是分区字段的情况下不会进行Mapreduce。
设置:
在hive-site.xml里面有个配置参数叫
hive.fetch.task.conversion = more
将这个参数设置为more,简单查询就不走map/reduce了,设置为minimal,就任何简单select都会走map/reduce
23、Map Join的原理和使用场景?
什么是MapJoin?
MapJoin顾名思义,就是在Map阶段进行表之间的连接。而不需要进入到Reduce阶段才进行连接。这样就节省了在Shuffle阶段时要进行的大量数据传输。从而起到了优化作业的作用。
MapJoin的原理:
即在map 端进行join,其原理是broadcast join,即把小表作为一个完整的驱动表来进行join操作。通常情况下,要连接的各个表里面的数据会分布在不同的Map中进行处理。即同一个Key对应的Value可能存在不同的Map中。这样就必须等到 Reduce中去连接。要使MapJoin能够顺利进行,那就必须满足这样的条件:除了一份表的数据分布在不同的Map中外,其他连接的表的数据必须在每 个Map中有完整的拷贝。MAPJION会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配 (这时可以使用DistributedCache将小表分发到各个节点上,以供Mapper加载使用),由于在map时进行了join操作,省去了reduce运行的效率也会高很多。
MapJoin适用的场景:
mapjoin的适用场景如关联操作中有一张表非常小,.不等值的链接操作。通过上面分析你会发现,并不是所有的场景都适合用MapJoin. 它通常会用在如下的一些情景:在二个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。这样我们就把小表文件复制到每一个Map任务的本地,再让Map
24、hive中order by、distribute by、sort by和cluster by的区别和联系
order by
order by 会对数据进行全局排序,和oracle和mysql等数据库中的order by 效果一样,它只在一个reduce中进行所以数据量特别大的时候效率非常低。
而且当设置 :set hive.mapred.mode=strict的时候不指定limit,执行select会报错,如下:
LIMIT must also be specified。
sort by
sort by 是单独在各自的reduce中进行排序,所以并不能保证全局有序,一般和distribute by 一起执行,而且distribute by 要写在sort by前面。
如果mapred.reduce.tasks=1和order by效果一样,如果大于1会分成几个文件输出每个文件会按照指定的字段排序,而不保证全局有序。
sort by 不受 hive.mapred.mode 是否为strict ,nostrict 的影响。
distribute by
DISTRIBUTE BY 控制map 中的输出在 reducer 中是如何进行划分的。使用DISTRIBUTE BY 可以保证相同KEY的记录被划分到一个Reduce 中。
cluster by
distribute by 和 sort by 合用就相当于cluster by,但是cluster by 不能指定排序为asc或 desc 的规则,只能是升序排列。
25、
